Generative Diffusion Models for Audio Inpainting
21.07.2023
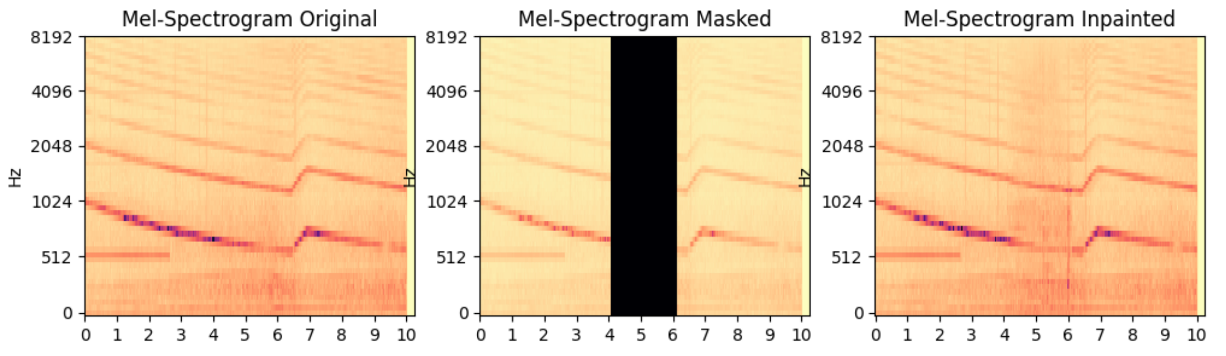
One of the most exciting projects I’ve worked on was my master's thesis, which focused on the use of generative diffusion models for audio inpainting and denoising. While these models have already shown impressive results in the image domain, their application to audio is still relatively new — and full of potential.
In this work, I explored how state-of-the-art inpainting techniques developed for images can be adapted to audio signals, which present unique challenges in terms of structure and representation. To do so, I worked with audio spectrograms rather than raw waveforms, allowing the models to more effectively identify and reproduce frequency patterns over time.
My experimentation began with AudioLDM, a text-to-audio diffusion model that uses a combination of contrastive pretraining and variational autoencoding. While this provided a strong baseline, the real breakthrough came from combining the Tango model (which uses FLAN-T5 for instruction-based conditioning) with the RePaint inference method — a technique that resamples intermediate diffusion steps to better harmonize generated content with known parts of the signal. This combination proved especially effective for reconstructing gaps in audio clips, even in complex soundscapes.
To evaluate performance, I used 24 samples from the AudioCaps dataset, introducing one- and two-second gaps and measuring reconstruction quality with metrics like SDR, SNR, PSNR, and SSIM. The Tango + RePaint setup consistently outperformed the baseline.
Finally, I extended the work to noisy communication scenarios, leveraging the Denoising Diffusion Null-Space Model (a method originally developed for images) to refine audio that had been corrupted during transmission. The results were remarkable, showing that even heavily degraded signals could be restored to near-original quality using this pipeline.
This thesis not only demonstrated the versatility of diffusion models in handling diverse audio restoration tasks, but also laid the groundwork for future applications including text-free inpainting and automatic post-denoising error correction, which are now being explored in an academic publication based on this work.
You can read the full thesis here, check out the ICASSP 2024 paper, or listen to the audio results.